

Unlocking New Insights with Existing Data
Platforms such as Databricks are increasingly becoming crucial for operational data analysis, thanks to their ability to unify data engineering, analytics, and machine learning in a single, scalable platform. With large historical datasets of operational data, firms in process industries such as oil and gas are finding that newer tools and technologies have the potential to unlock insights that were previously out of reach. However, many firms struggle with getting their operational data into these analytical platforms. Integrating AVEVA PI to Databricks and Azure is a key step toward overcoming this challenge and enabling advanced AI-driven analytics.
One such oil and gas organization defined a project centered on migrating vast volumes of operational data, including sensor readings from AVEVA PI and high-resolution inspection images, from legacy on-premises systems to a centralized cloud platform, Azure Data Lake Storage. The objective was to build a scalable foundation to support advanced analytics and machine learning workloads while ensuring alignment with existing tools and workflows.
Obstacles to Data Integration
There were several challenges this company faced when embarking on the project.
Data Volume
Over a decade of historical sensor data, captured in PI and accessed through the PI System’s Asset Framework (AF), spanned more than half a million sensors across multiple facilities and was stored in various historians. This vast dataset needed to be migrated to the cloud, with Azure Data Lake Storage serving as the centralized destination.
File Formats
The legacy systems did not natively support modern data formats such as Parquet and lacked direct integration with Azure Data Lake Storage, turning data migration into a complex and time-intensive task that required careful orchestration. Processing high volumes of data frequently led to elevated CPU usage, resulting in system performance bottlenecks.
Complicated Data Pipeline
The data pipeline also depended on a layered network of cloud services, all of which required continuous monitoring to ensure reliable data flow from source to destination. This architecture introduced additional latency and complexity, especially due to the intermediary components involved. Compounding these challenges was the lack of built-in verification mechanisms, which meant data integrity and completeness could not be automatically validated after each transfer.
Transferring Image Files to Azure Data Lake Storage
To address these challenges, SignalX was deployed to monitor designated network folders and subdirectories, automatically detect newly added image files, and transfer them to Azure Data Lake Storage in near real time. This enabled seamless access for downstream analytics in Azure Databricks with minimal delay after capture.
SignalX: Modernizing Data Flow for Cloud Analytics
SignalX was selected as the solution to remediate these challenges and achieve the integration and analytical goals outlined by the project. SignalX provides native connectivity to AVEVA PI, Asset Framework, Databricks, Azure Data Lake Storage, Azure Event Hub, Azure IoT Hub, and many other endpoints that were relevant to this solution. SignalX was used to send data from file storage and AVEVA PI to Azure Data Lake and Databricks.
Solution Overview
To address these complex integration challenges, SignalX delivered a robust and scalable solution designed to modernize data movement and streamline cloud analytics workflows. The approach focused on the efficient transfer of combined sensor data from multiple AVEVA PI facilities and image data from legacy on-premises systems to Azure Data Lake Storage, while also enabling the seamless return of machine learning outputs into existing on-premises historian environments.
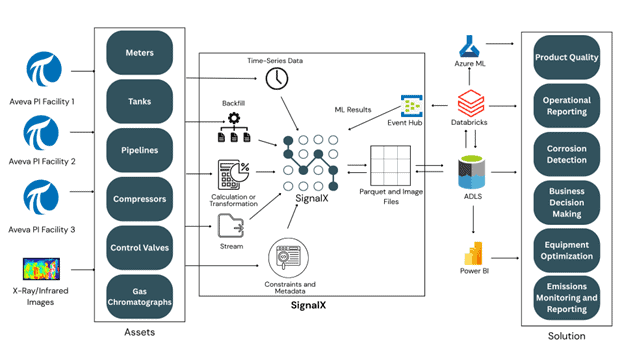
Streaming Sensor Data to Azure Data Lake Storage with SignalX
SignalX streamlined the delivery of sensor data to Azure Data Lake Storage by leveraging the high-performance Parquet file format. Compared to traditional JSON, Parquet’s compressed binary structure significantly enhanced efficiency across network transfer, disk I/O, and cloud-based processing workloads.
By sourcing data directly from the PI System via Asset Framework, SignalX eliminated the need for custom scripts to transform historian data into Parquet format. This reduced setup time and simplified operations. With built-in asset search capabilities, users could avoid manually specifying individual assets, attributes, or tags. This not only accelerated configuration but also minimized long-term maintenance. Flexible filters allowed irrelevant assets to be excluded, and advanced data transformations aligned sensor readings to relevant time series events.
SignalX supported interpolated, raw, and averaged data retrieval, and enabled pivoted tabular outputs—capabilities often requiring custom development in other platforms. It also enriched the dataset with time series metadata to enhance downstream reporting and analytics. End-to-end validation mechanisms ensured accuracy and completeness of all data written to Azure Data Lake Storage, maintaining data integrity throughout the pipeline.
Transferring Image Files to Azure Data Lake Storage with SignalX
SignalX monitored designated network folders, including all subdirectories, and automatically detected when new image files were added. As soon as the files were ready, they were transferred to Azure Data Lake Storage in near real time, enabling immediate availability for machine learning–based visual inspection and analysis workflows.
Writing Machine Learning Results Back to On-Premises PI Historian
After processing data in the cloud and generating insights through machine learning, the results needed to be written back into the on-premises PI historian systems and Asset Framework. This ensured that existing tools and workflows could continue to access and act on the latest intelligence without disruption.
Results
The deployment of SignalX led to immediate, measurable improvements across the entire data integration pipeline.
- ✅ Removal of Performance Bottlenecks – by leveraging binary-compressed Parquet files and direct transfer to Azure Data Lake Storage.
- ✅ Handling High-Volume Workloads – event-driven detection enabled both sensor data and high-resolution images to be transferred to Azure Data Lake.
- ✅ Reducing Setup Time and Maintenance – automatic asset detection and writing machine learning results back to on-premises PI historians with no custom scripting and maintaining compatibility with existing tools and workflows.
- ✅ Maintaining Data Quality and Integrity – built-in validation and statistical checks verified that all transferred data accurately reflected the source
Contact Us
Looking to unlock the full potential of your operational data? SignalX enables seamless integration between AVEVA PI, Azure Data Lake Storage, and Databricks by streamlining historian data migration, supporting advanced analytics, and modernizing legacy pipelines. Whether you’re aiming to adopt AI faster or improve real-time data access for analytics, SignalX delivers scalable solutions tailored for industrial needs. To learn more, contact us at [email protected].